Continuous Offensive Security Testing (COST) that fires on every change.
FireCompass runs trigger-driven web and API pentests the moment you deploy, expose a new asset, or a fresh CVE drops. Every finding ships with a working exploit. Under 2% false positives.
What is Continuous Offensive Security Testing?
Continuous Offensive Security Testing (COST) is a trigger-driven model that replaces annual, calendar-based pentesting with offensive testing that starts when something material changes: a deployment, a new asset, a fresh CVE, or configuration drift. It unifies discovery, penetration testing, attack-chain validation, and red teaming into one continuously operating capability.
Annual pentesting was built for software that shipped once a quarter.
That world is gone. Teams deploy weekly or daily, and attackers now move at machine speed. Three structural gaps open the moment testing runs on a calendar.
Tested vs attacked
Most programs test crown-jewel apps and leave shadow apps, forgotten subdomains, and API endpoints untouched. Attackers probe 100% of the surface.
Scanner false positives
Scanners flag issues in isolation. Real attackers chain them. 22% of breaches start with credential abuse, and 20% begin through a peripheral asset.
vs a 3-day exploit window
Many teams still test once a year. Attackers exploit new CVEs in about 3 days. The gap widens with every release you ship.
Four capabilities, each tied to a trigger.
A change happens, a test fires. No scheduling, no human in the critical path.
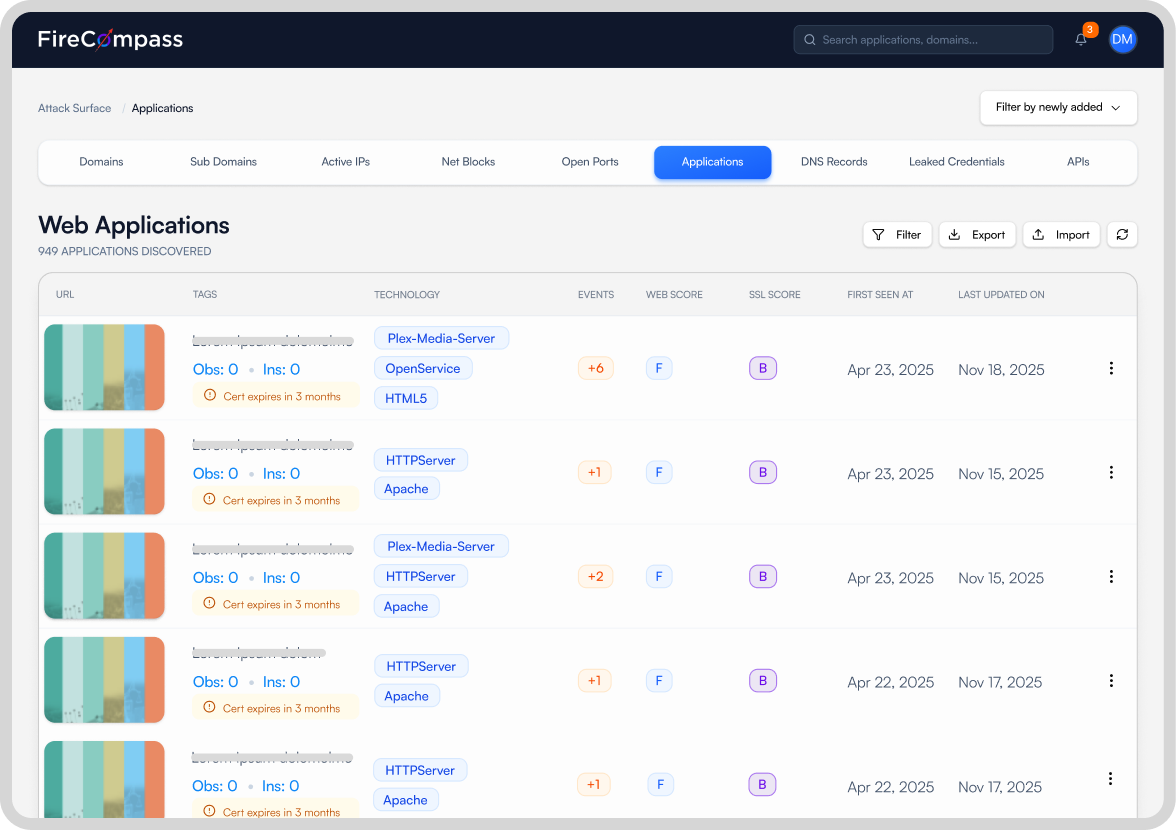
Discover the surface attackers actually see
Build your real attack surface from your name alone, so testing covers what attackers can actually reach.
- Shadow apps and forgotten subdomains surfaced from your name alone.
- Leaked credentials on the deep and dark web.
- API endpoints pulled from JS files and traffic.
- Visibility scales from about 20% to over 99% of the surface.
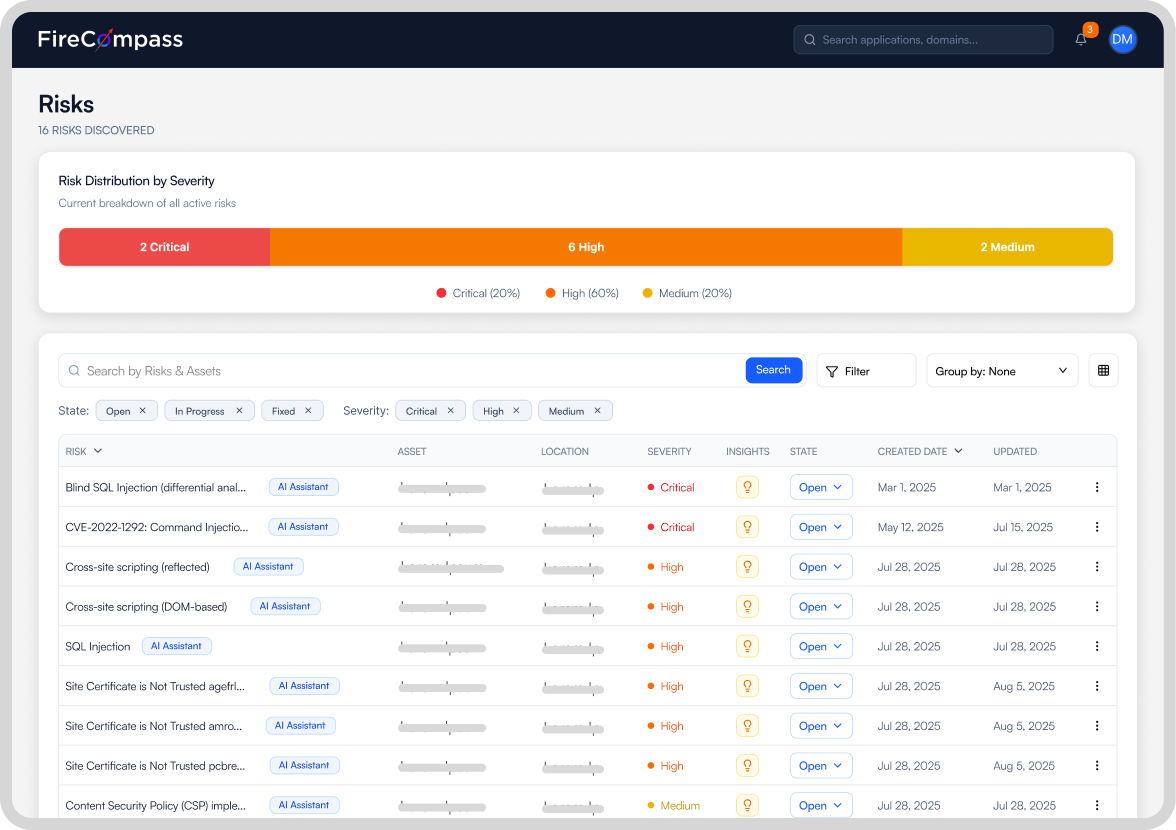
Pentest with proof, not noise
Agents test like an attacker and confirm what is real, so your team triages exploitable findings, not false alarms.
- OWASP Top 10: 2025 plus business logic testing.
- Authenticated and unauthenticated paths, including MFA flows.
- Credential abuse and authorization testing.
- Every finding ships proof of exploit, steps to reproduce, and ready-to-run Python.
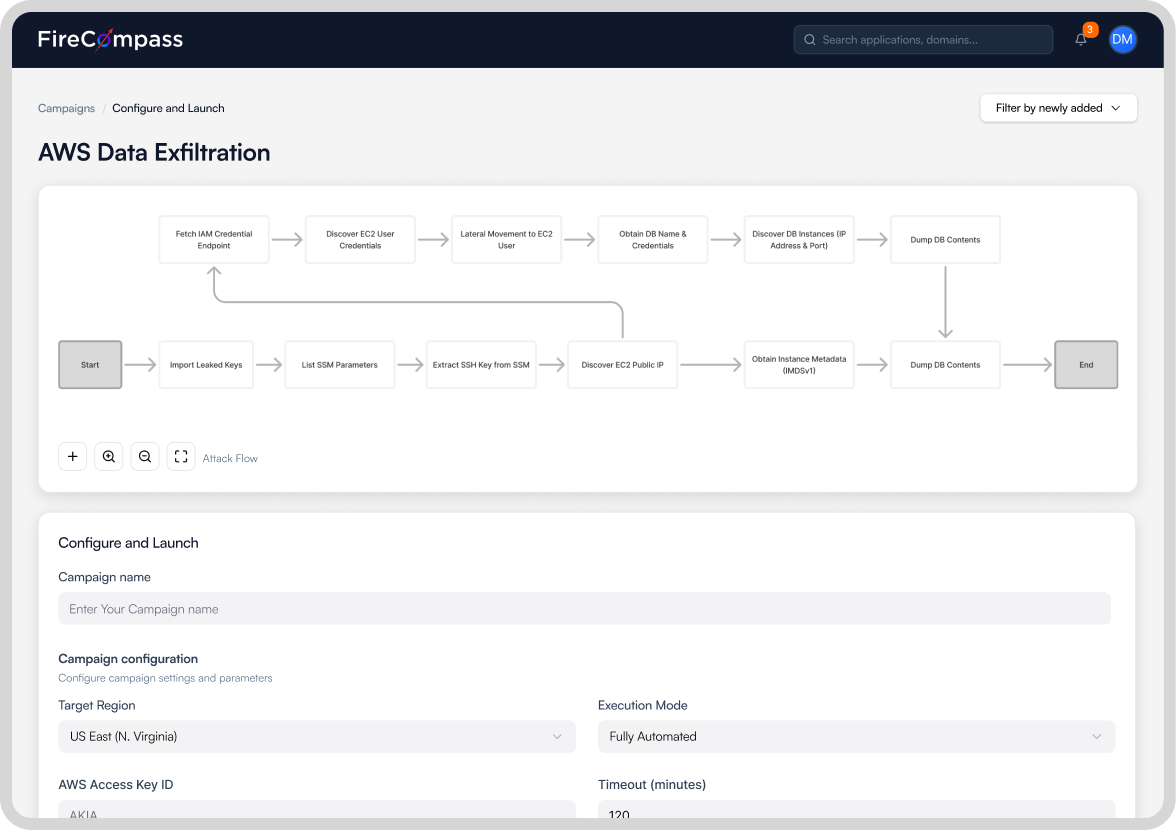
Chain findings into real attack paths
A single finding is rarely the breach. Agents connect findings the way real adversaries do in multi-stage red teaming, showing true blast radius.
- Credential reuse across services.
- App-to-app and app-to-network lateral movement.
- Privilege escalation path discovery.
- Full MITRE ATT&CK kill-chain automation, no human steering.
Run on your cadence, not a calendar
Testing keeps pace with how fast you ship, so the window between a change and its validation closes to near zero.
- Weekly, on demand, or aligned to CI/CD.
- Day-1 CVE validation for new disclosures.
- One-click revalidation to confirm fixes.
- Agentless and operational in minutes.
Run COST against your own attack surface.
Start free, or connect with a FireCompass expert. In one session you will:
- ✓See shadow apps, subdomains, and exposed APIs discovered from your name alone.
- ✓Watch an agent validate a real finding with a working proof-of-concept exploit.
- ✓Set the triggers that fire a test on every deploy, new asset, and fresh CVE.
Exploit-validated findings, benchmarked in the open.
One finding became a full compromise
- Exposed .git. The agent reconstructed the repo and pulled database credentials from config files.
- Direct DB access blocked. The port was not externally exposed. A scanner stops here.
- Credential reuse to SSH root. The agent tested the same creds against SSH and gained root.
- Internal pivot to data exfiltration. From the server it found private keys, pivoted, and dumped the database.
- No human steering. No predefined playbook. Agents beat our top researchers 60 to 70% of the time in internal evals.
Fortune 500: annual program to continuous
Before → AfterMost "continuous" platforms solve one gap and ignore the other two.
Continuous DAST gives speed without depth. PTaaS gives depth without scope or cadence. ASM gives scope without validation. BAS simulates attacks instead of executing them. COST does all of it, with every exploit proven.
| Capability | Continuous DAST | Human-led PTaaS | Continuous ASM | Breach & attack simulation | FireCompass |
|---|---|---|---|---|---|
| Full attack-surface scope | Partial | Scoped slice | Yes | Control-focused | Yes |
| Business-logic depth | No | Manual | No | No | AI-driven |
| Multi-stage attack chains | No | Manual | No | Simulated | Autonomous |
| Exploit-validated PoC | No | Yes | No | Simulated | Every finding |
| Trigger-driven cadence | Yes | Weeks | Yes | Continuous | On every change |
| Cost per app | $1,460–$2,900 | $2,400–$10,000 | Low | Platform fee | $450–$2,500 |
| False positive rate | up to 70% | Variable | High | Variable | Under 2% |
| Governance & audit trail | Partial | Manual | Partial | Partial | Built in |
Continuous only works if it is safe to run in production.
One of the analyst firm says the governance layer is the part the market underestimates most. It is where we built first.
- ✓Scope enforcement. Agents act only within defined boundaries. Nothing tests outside the authorized surface.
- ✓Production-safe execution. Rate limits and control gates keep live systems stable while testing runs.
- ✓Forensic audit trail. Every command, request, and response is timestamped for non-repudiation and review.
- ✓Human-in-the-loop, optional. Run fully autonomous, or keep an expert validating before action.
- ✓Kill switches. Stop any engagement instantly. Control over what agents can and cannot do is the design principle.
Validated by the analysts who define the category.
Listed in "The Future of Pen Testing Is Continuous Offensive Security Testing".
XBEN 104/104, Acuart 12/12 PoC-validated, and DVWA, fully autonomous with no human hints.
Across Forrester, IDC, GigaOm and a leading gloabl research firm. GigaOm Leader, 2023. On the technology maturity index five cycles running.
COST, answered.
What is Continuous Offensive Security Testing (COST)?
How is COST different from annual penetration testing?
How does COST relate to CTEM?
Is continuous offensive testing safe to run in production?
How fast does a test run, and what does it cost?
What does FireCompass test?
For security professionals
Run your first trigger-driven web and API pentest this week. No install, results in about a day.
Free AI Pen Test →